User-Defined Functions (UDF) explained#
While openEO supports a wide range of pre-defined processes and allows to build more complex user-defined processes from them, you sometimes need operations or algorithms that are not (yet) available or standardized as openEO process. User-Defined Functions (UDF) is an openEO feature (through the run_udf process) that aims to fill that gap by allowing a user to express (a part of) an algorithm as a Python/R/… script to be run back-end side.
There are a lot of details to cover, but here is a rudimentary example snippet to give you a quick impression of how to work with UDFs using the openEO Python Client library:
import openeo
# Build a UDF object from an inline string with Python source code.
udf = openeo.UDF(
"""
import xarray
def apply_datacube(cube: xarray.DataArray, context: dict) -> xarray.DataArray:
cube.values = 0.0001 * cube.values
return cube
"""
)
# Or load the UDF code from a separate file.
# udf = openeo.UDF.from_file("udf-code.py")
# Apply the UDF to a cube.
rescaled_cube = cube.apply(process=udf)
Ideally, it allows you to embed existing Python/R/… implementations in an openEO workflow (with some necessary “glue code”). However, it is recommended to try to do as much pre- or postprocessing with pre-defined processes before blindly copy-pasting source code snippets as UDFs. Pre-defined processes are typically well-optimized by the backend, while UDFs can come with a performance penalty and higher development/debug/maintenance costs.
Warning
Don not confuse user-defined functions (abbreviated as UDF) with user-defined processes (sometimes abbreviated as UDP) in openEO, which is a way to define and use your own process graphs as reusable building blocks. See User-Defined Processes (UDP) for more information.
Applicability and Constraints#
openEO is designed to work transparently on large data sets and your UDF has to follow a couple of guidelines to make that possible. First of all, as data cubes play a central role in openEO, your UDF should accept and return correct data cube structures, with proper dimensions, dimension labels, etc. Moreover, the back-end will typically divide your input data cube in smaller chunks and process these chunks separately (e.g. on isolated workers). Consequently, it’s important that your UDF algorithm operates correctly in such a chunked processing context.
A very common mistake is to use index-based array indexing, rather than name based. The index based approach assumes that datacube dimension order is fixed, which is not guaranteed. Next to that, it also reduces the readability of your code. Label based indexing is a great feature of xarray, and should be used whenever possible.
As a rule of thumb, the UDF should preserve the dimensions and shape of the input data cube. The datacube chunk that is passed on by the backend does not have a fixed specification, so the UDF needs to be able to accomodate different shapes and sizes of the data.
There’s important exceptions to this rule, that depend on the context in which the UDF is used. For instance, a UDF used as a reducer should effectively remove the reduced dimension from the output chunk. These details are documented in the next sections.
UDFs as apply/reduce “callbacks”#
UDFs are typically used as “callback” processes for “meta” processes
like apply or reduce_dimension (also see Processes with child “callbacks”).
These meta-processes make abstraction of a datacube as a whole
and allow the callback to focus on a small slice of data or a single dimension.
Their nature instructs the backend how the data should be processed
and can be chunked:
- apply
Applies a process on each pixel separately. The back-end has all freedom to choose chunking (e.g. chunk spatially and temporally). Dimensions and their labels are fully preserved. This function has limited practical use in combination with UDF’s.
- apply_dimension
Applies a process to all pixels along a given dimension to produce a new series of values for that dimension. The back-end will not split your data on that dimension. For example, when working along the time dimension, your UDF is guaranteed to receive a full timeseries, but the data could be chunked spatially. All dimensions and labels are preserved, except for the dimension along which
apply_dimensionis applied: the number of dimension labels is allowed to change.- reduce_dimension
Applies a process to all pixels along a given dimension to produce a single value, eliminating that dimension. Like with
apply_dimension, the back-end will not split your data on that dimension. The dimension along whichapply_dimensionis applied must be removed from the output. For example, when applyingreduce_dimensionon a spatiotemporal cube along the time dimension, the UDF is guaranteed to receive full timeseries (but the data could be chunked spatially) and the output cube should only be a spatial cube, without a temporal dimension- apply_neighborhood
Applies a process to a neighborhood of pixels in a sliding-window fashion with (optional) overlap. Data chunking in this case is explicitly controlled by the user. Dimensions and number of labels are fully preserved. This is the most versatile and widely used function to work with UDF’s.
UDF function names and signatures#
The UDF code you pass to the back-end is basically a Python script
that contains one or more functions.
Exactly one of these functions should have a proper UDF signature,
as defined in the openeo.udf.udf_signatures module,
so that the back-end knows what the entrypoint function is
of your UDF implementation.
Module openeo.udf.udf_signatures#
This module defines a number of function signatures that can be implemented by UDF’s. Both the name of the function and the argument types are/can be used by the backend to validate if the provided UDF is compatible with the calling context of the process graph in which it is used.
- openeo.udf.udf_signatures.apply_datacube(cube, context)[source]#
Map a
xarray.DataArrayto anotherxarray.DataArray.Depending on the context in which this function is used, the
xarray.DataArraydimensions have to be retained or can be chained. For instance, in the context of a reducing operation along a dimension, that dimension will have to be reduced to a single value. In the context of a 1 to 1 mapping operation, all dimensions have to be retained.
- openeo.udf.udf_signatures.apply_metadata(metadata, context)[source]#
Warning
This signature is not yet fully standardized and subject to change.
Returns the expected cube metadata, after applying this UDF, based on input metadata. The provided metadata represents the whole raster or vector cube. This function does not need to be called for every data chunk.
When this function is not implemented by the UDF, the backend may still be able to infer correct metadata by running the UDF, but this can result in reduced performance or errors.
This function does not need to be provided when using the UDF in combination with processes that by design have a clear effect on cube metadata, such as
reduce_dimension()- Parameters:
metadata (
CollectionMetadata) – the collection metadata of the input data cubecontext (
dict) – A dictionary containing user context.
- Return type:
- Returns:
output metadata: the expected metadata of the cube, after applying the udf
Examples#
An example for a UDF that is applied on the ‘bands’ dimension, and returns a new set of bands with different labels.
>>> def apply_metadata(metadata: CollectionMetadata, context: dict) -> CollectionMetadata: ... return metadata.rename_labels( ... dimension="bands", ... target=["computed_band_1", "computed_band_2"] ... )
- openeo.udf.udf_signatures.apply_timeseries(series, context)[source]#
Process a timeseries of values, without changing the time instants.
This can for instance be used for smoothing or gap-filling.
- Parameters:
series (
Series) – A Pandas Series object with a date-time index.context (
dict) – A dictionary containing user context.
- Return type:
Series- Returns:
A Pandas Series object with the same datetime index.
- openeo.udf.udf_signatures.apply_udf_data(data)[source]#
Generic UDF function that directly manipulates a
UdfDataobject- Parameters:
data (
UdfData) –UdfDataobject to manipulate in-place
- openeo.udf.udf_signatures.apply_vectorcube(geometries, cube, context)[source]#
Map a vector cube to another vector cube.
- Parameters:
geometries (
GeoDataFrame) – input geometries as a geopandas.GeoDataFrame. This contains the actual shapely geometries and optional properties.cube (
DataArray) – a data cube with dimensions (geometries, time, bands) where time and bands are optional. The coordinates for the geometry dimension are integers and match the index of the geometries in the geometries parameter.context (
dict) – A dictionary containing user context.
- Return type:
(geopandas.geodataframe.GeoDataFrame,
DataArray)- Returns:
output geometries, output data cube
A first example: apply with an UDF to rescale pixel values#
In most of the examples here, we will start from an initial Sentinel2 data cube like this:
s2_cube = connection.load_collection(
"SENTINEL2_L2A",
spatial_extent={"west": 4.00, "south": 51.04, "east": 4.10, "north": 51.1},
temporal_extent=["2022-03-01", "2022-03-31"],
bands=["B02", "B03", "B04"],
)
The raw values in this initial s2_cube data cube are digital numbers
(integer values ranging from 0 to several thousands)
and to get physical reflectance values (float values, typically in the range between 0 and 0.5),
we have to rescale them.
This is a simple local transformation, without any interaction between pixels,
which is the modus operandi of the apply processes.
Note
In practice it will be a lot easier and more efficient to do this kind of rescaling
with pre-defined openEO math processes, for example: s2_cube.apply(lambda x: 0.0001 * x).
This is just a very simple illustration to get started with UDFs. In fact, it’s very likely that
you will never want to use a UDF with apply.
UDF script#
The UDF code is this short script (the part that does the actual value rescaling is highlighted):
udf-code.py#1import xarray
2
3
4def apply_datacube(cube: xarray.DataArray, context: dict) -> xarray.DataArray:
5 cube.values = 0.0001 * cube.values
6 return cube
Some details about this UDF script:
line 1: We import xarray as we use this as exchange format.
line 3: We define a function named
apply_datacube, which receives and returns aDataArrayinstance. We follow here theapply_datacube()UDF function signature.line 4: Because our scaling operation is so simple, we can transform the
xarray.DataArrayvalues in-place.line 5: Consequently, because the values were updated in-place, we can return the same Xarray object.
Workflow script#
In this first example, we’ll cite a full, standalone openEO workflow script, including creating the back-end connection, loading the initial data cube and downloading the result. The UDF-specific part is highlighted.
Warning
This implementation depends on openeo.UDF improvements
that were introduced in version 0.13.0 of the openeo Python Client Library.
If you are currently stuck with working with an older version,
check openeo.UDF API and usage changes in version 0.13.0 for more information on the difference with the old API.
1import openeo
2
3# Create connection to openEO back-end
4connection = openeo.connect("...").authenticate_oidc()
5
6# Load initial data cube.
7s2_cube = connection.load_collection(
8 "SENTINEL2_L2A",
9 spatial_extent={"west": 4.00, "south": 51.04, "east": 4.10, "north": 51.1},
10 temporal_extent=["2022-03-01", "2022-03-31"],
11 bands=["B02", "B03", "B04"],
12)
13
14# Create a UDF object from inline source code.
15udf = openeo.UDF(
16"""
17import xarray
18
19def apply_datacube(cube: xarray.DataArray, context: dict) -> xarray.DataArray:
20 cube.values = 0.0001 * cube.values
21 return cube
22"""
23)
24
25# Pass UDF object as child process to `apply`.
26rescaled = s2_cube.apply(process=udf)
27
28rescaled.download("apply-udf-scaling.nc")
In line 15, we build an openeo.UDF object
from an inline string with the UDF source code.
This openeo.UDF object encapsulates various aspects
that are necessary to create a run_udf node in the process graph,
and we can pass it directly in line 25 as the process argument
to DataCube.apply().
Tip
Instead of putting your UDF code in an inline string like in the example,
it’s often a good idea to load the UDF code from a separate file,
which is easier to maintain in your preferred editor or IDE.
You can do that directly with the
openeo.UDF.from_file method:
udf = openeo.UDF.from_file("udf-code.py")
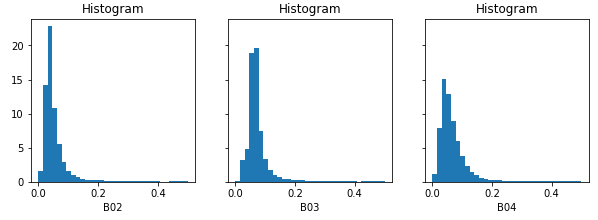
After downloading the result, we can inspect the band values locally. Note see that they fall mainly in a range from 0 to 1 (in most cases even below 0.2), instead of the original digital number range (thousands):
UDF’s that transform cube metadata#
Warning
This is a new/experimental feature so may still be subject to change.
In some cases, a UDF can have impact on the metadata of a cube, but this can not always be easily inferred by process graph evaluation logic without running the actual (expensive) UDF code. This limits the possibilities to validate process graphs, or for instance make an estimate of the size of a datacube after applying a UDF.
To provide evaluation logic with this information, the user should implement the
apply_metadata() function as part of the UDF.
Please refer to the documentation of that function for more information.
udf_modify_spatial.py#import numpy as np
import xarray
from openeo.metadata import CollectionMetadata
from openeo.udf.debug import inspect
def apply_metadata(input_metadata: CollectionMetadata, context: dict) -> CollectionMetadata:
res= [ d.step / 2.0 for d in input_metadata.spatial_dimensions]
return input_metadata.resample_spatial(resolution=res)
def fancy_upsample_function(array: np.array, factor: int = 2) -> np.array:
assert array.ndim == 3
return array.repeat(factor, axis=-1).repeat(factor, axis=-2)
def apply_datacube(cube: xarray.DataArray, context: dict) -> xarray.DataArray:
cubearray: xarray.DataArray = cube.copy() + 60
# We make prediction and transform numpy array back to datacube
# Pixel size of the original image
init_pixel_size_x = cubearray.coords["x"][-1].item() - cubearray.coords["x"][-2].item()
init_pixel_size_y = cubearray.coords["y"][-1].item() - cubearray.coords["y"][-2].item()
if cubearray.data.ndim == 4 and cubearray.data.shape[0] == 1:
cubearray = cubearray[0]
predicted_array = fancy_upsample_function(cubearray.data, 2)
inspect(data=predicted_array, message=f"predicted array")
coord_x = np.linspace(
start=cube.coords["x"][0].item(),
stop=cube.coords["x"][-1].item() + init_pixel_size_x,
num=predicted_array.shape[-2],
endpoint=False,
)
coord_y = np.linspace(
start=cube.coords["y"].min().item(),
stop=cube.coords["y"].max().item() + init_pixel_size_y,
num=predicted_array.shape[-1],
endpoint=False,
)
predicted_cube = xarray.DataArray(
predicted_array,
dims=["bands", "x", "y"],
coords=dict(x=coord_x, y=coord_y),
)
return predicted_cube
To invoke a UDF like this, the apply_neighborhood method is most suitable:
udf = openeo.UDF.from_file("udf_modify_spatial.py", runtime="Python-Jep")
cube_updated = cube.apply_neighborhood(
udf,
size=[
{"dimension": "x", "value": 128, "unit": "px"},
{"dimension": "y", "value": 128, "unit": "px"},
],
overlap=[],
)
Example: apply_dimension with a UDF#
This is useful when running custom code over all band values for a given pixel or all observations per pixel. See section below ‘Smoothing timeseries with a user defined function’ for a concrete example.
Example: reduce_dimension with a UDF#
The key element for a UDF invoked in the context of reduce_dimension is that it should actually return an Xarray DataArray _without_ the dimension that is specified to be reduced.
So a reduce over time would receive a DataArray with bands,t,y,x dimensions, and return one with only bands,y,x.
Example: apply_neighborhood with a UDF#
The apply_neighborhood process is generally used when working with complex AI models that require a spatiotemporal input stack with a fixed size. It supports the ability to specify overlap, to ensure that the model has sufficient border information to generate a spatially coherent output across chunks of the raster data cube.
In the example below, the UDF will receive chunks of 128x128 pixels: 112 is the chunk size, while 2 times 8 pixels of overlap on each side of the chunk results in 128.
The time and band dimensions are not specified, which means that all values along these dimensions are passed into the datacube.
output_cube = inputs_cube.apply_neighborhood(
my_udf,
size=[
{"dimension": "x", "value": 112, "unit": "px"},
{"dimension": "y", "value": 112, "unit": "px"},
],
overlap=[
{"dimension": "x", "value": 8, "unit": "px"},
{"dimension": "y", "value": 8, "unit": "px"},
],
)
Warning
The apply_neighborhood is the most versatile, but also most complex process. Make sure to keep an eye on the dimensions
and the shape of the DataArray returned by your UDF. For instance, a very common error is to somehow ‘flip’ the spatial dimensions.
Debugging the UDF locally can help, but then you will want to try and reproduce the input that you get also on the backend.
This can typically be achieved by using logging to inspect the DataArrays passed into your UDF backend side.
Example: Smoothing timeseries with a user defined function (UDF)#
In this example, we start from the evi_cube that was created in the previous example, and want to
apply a temporal smoothing on it. More specifically, we want to use the “Savitzky Golay” smoother
that is available in the SciPy Python library.
To ensure that openEO understand your function, it needs to follow some rules, the UDF specification. This is an example that follows those rules:
smooth_savitzky_golay.py#import xarray
from scipy.signal import savgol_filter
from openeo.udf import XarrayDataCube
def apply_datacube(cube: XarrayDataCube, context: dict) -> XarrayDataCube:
"""
Apply Savitzky-Golay smoothing to a timeseries datacube.
This UDF preserves dimensionality, and assumes an input
datacube with a temporal dimension 't' as input.
"""
array: xarray.DataArray = cube.get_array()
filled = array.interpolate_na(dim="t")
smoothed_array = savgol_filter(filled.values, 5, 2, axis=0)
return XarrayDataCube(array=xarray.DataArray(smoothed_array, dims=array.dims, coords=array.coords))
The method signature of the UDF is very important, because the back-end will use it to detect
the type of UDF.
This particular example accepts a DataCube object as input and also returns a DataCube object.
The type annotations and method name are actually used to detect how to invoke the UDF, so make sure they remain unchanged.
Once the UDF is defined in a separate file, we load it and apply it along a dimension:
smoothing_udf = openeo.UDF.from_file("smooth_savitzky_golay.py")
smoothed_evi = evi_cube_masked.apply_dimension(smoothing_udf, dimension="t")
Downloading a datacube and executing an UDF locally#
Sometimes it is advantageous to run a UDF on the client machine (for example when developing/testing that UDF).
This is possible by using the convenience function openeo.udf.run_code.execute_local_udf().
The steps to run a UDF (like the code from smooth_savitzky_golay.py above) are as follows:
Run the processes (or process graph) preceding the UDF and download the result in ‘NetCDF’ or ‘JSON’ format.
Run
openeo.udf.run_code.execute_local_udf()on the data file.
For example:
from pathlib import Path
from openeo.udf import execute_local_udf
my_process = connection.load_collection(...
my_process.download('test_input.nc', format='NetCDF')
smoothing_udf = Path('smooth_savitzky_golay.py').read_text()
execute_local_udf(smoothing_udf, 'test_input.nc', fmt='netcdf')
Note: this algorithm’s primary purpose is to aid client side development of UDFs using small datasets. It is not designed for large jobs.
UDF dependency management#
UDFs usually have some dependencies on existing libraries, e.g. to implement complex algorithms.
In case of Python UDFs, it can be assumed that common libraries like numpy and Xarray are readily available,
not in the least because they underpin the Python UDF function signatures.
More concretely, it is possible to inspect available libraries for the available UDF runtimes
through Connection.list_udf_runtimes().
For example, to list the available libraries for runtime “Python” (version “3”):
>>> connection.list_udf_runtimes()["Python"]["versions"]["3"]["libraries"]
{'geopandas': {'version': '0.13.2'},
'numpy': {'version': '1.22.4'},
'xarray': {'version': '0.16.2'},
...
Managing and using additional dependencies or libraries that are not provided out-of-the-box by a backend is a more challenging problem and the practical details can vary between backends.
Standard for declaring Python UDF dependencies#
Warning
This is based on a fairly recent standard and it might not be supported by your chosen backend yet.
PEP 723 “Inline script metadata” defines a standard
for Python scripts to declare dependencies inside a top-level comment block.
If the openEO backend of your choice supports this standard, it is the preferred approach
to declare the (import) dependencies of your Python UDF:
It avoids all the overhead for the UDF developer to correctly and efficiently make desired dependencies available in the UDF.
It allows the openEO backend to optimize dependencies handling.
Warning
An openEO backend might only support this automatic UDF dependency handling feature in batch jobs (because of their isolated nature), but not for synchronous processing requests.
Declaration of UDF dependencies#
A basic example of how the UDF dependencies can be declared in top-level comment block of your Python UDF:
# /// script
# dependencies = [
# "geojson",
# "fancy-eo-library",
# ]
# ///
#
# This openEO UDF script implements ...
# based on the fancy-eo-library ... using geosjon data ...
import geojson
import fancyeo
def apply_datacube(cube: xarray.DataArray, context: dict) -> xarray.DataArray:
...
Some considerations to make sure you have a valid metadata block:
Lines start with a single hash
#and one space (the space can be omitted if the#is the only character on the line).The metadata block starts with a line
# /// scriptand ends with# ///.Between these delimiters you put the metadata fields in TOML format, each line prefixed with
#and a space.Declare your UDF’s dependencies in a
dependenciesfield as a TOML array. List each package on a separate line as shown above, or put them all on a single line. It is also allowed to include comments, as long as the whole construct is valid TOML.Each
dependenciesentry must be a valid PEP 508 dependency specifier. This practically means to use the package names (optionally with version constraints) as expected by thepip installcommand.
A more complex example to illustrate some more advanced aspects of the metadata block:
# /// script
# dependencies = [
# # A comment about using at least version 2.5.0
# 'geojson>=2.5.0', # An inline comment
# # Note that TOML allows both single and double quotes for strings.
#
# # Install a package "fancyeo" from a (ZIP) source archive URL.
# "fancyeo @ https://github.com/fncy/fancyeo/archive/refs/tags/v3.2.0-alpha1.zip",
# # Or from a wheel URL, including a content hash to be verified before installing.
# "lousyeo @ https://example.com/lousyeo-6.6.6-py3-none-any.whl#sha1=4bbb3c72a9234ee998a6de940a148e346a",
# # Note that the last entry may have a trailing comma.
# ]
# ///
Verification#
Use extract_udf_dependencies() to verify
that your metadata block can be parsed correctly:
>>> from openeo.udf.run_code import extract_udf_dependencies
>>> extract_udf_dependencies(udf_code)
['geojson>=2.5.0',
'fancyeo @ https://github.com/fncy/fancyeo/archive/refs/tags/v3.2.0-alpha1.zip',
'lousyeo @ https://example.com/lousyeo-6.6.6-py3-none-any.whl#sha1=4bbb3c72a9234ee998a6de940a148e346a']
If no valid metadata block is found, None will be returned.
Note
This function won’t necessarily raise exceptions for syntax errors in the metadata block. It might just fail to reliably detect anything and skip it as regular comment lines.
Ad-hoc dependency handling#
If dependency handling through standardized UDF declarations is not supported by the backend, there are still ways to manually handle additional dependencies in your UDF. The exact details can vary between backends, but we can give some general pointers here:
Multiple Python dependencies can be packaged fairly easily by zipping a Python virtual environment.
For some dependencies, it can be important that the Python major version of the virtual environment is the same as the one used by the backend.
Python allows you to dynamically append (or prepend) libraries to the search path:
sys.path.append("unzipped_virtualenv_location")
Profile a process server-side#
Warning
Experimental feature - This feature only works on back-ends running the Geotrellis implementation, and has not yet been adopted in the openEO API.
Sometimes users want to ‘profile’ their UDF on the back-end. While it’s recommended to first profile it offline, in the same manner as you can debug UDF’s, back-ends may support profiling directly. Note that this will only generate statistics over the python part of the execution, therefore it is only suitable for profiling UDFs.
Usage#
Only batch jobs are supported! In order to turn on profiling, set ‘profile’ to ‘true’ in job options:
job_options={'profile':'true'}
... # prepare the process
process.execute_batch('result.tif',job_options=job_options)
When the process has finished, it will also download a file called ‘profile_dumps.tar.gz’:
rdd_-1.pstatsis the profile data of the python driver,the rest are the profiling results of the individual rdd id-s (that can be correlated with the execution using the SPARK UI).
Viewing profiling information#
The simplest way is to visualize the results with a graphical visualization tool called kcachegrind. In order to do that, install kcachegrind packages (most linux distributions have it installed by default) and it’s python connector pyprof2calltree. From command line run:
pyprof2calltree rdd_<INTERESTING_RDD_ID>.pstats.
Another way is to use the builtin pstats functionality from within python:
import pstats
p = pstats.Stats('restats')
p.print_stats()
Example#
An example code can be found here .
Logging from a UDF#
From time to time, when things are not working as expected,
you may want to log some additional debug information from your UDF, inspect the data that is being processed,
or log warnings.
This can be done using the inspect() function.
For example: to discover the shape of the data cube chunk that you receive in your UDF function:
inspect() logging#from openeo.udf import inspect
import xarray
def apply_datacube(cube: xarray.DataArray, context: dict) -> xarray.DataArray:
inspect(data=[cube.shape], message="UDF logging shape of my cube")
cube.values = 0.0001 * cube.values
return cube
After the batch job is finished (or failed), you can find this information in the logs of the batch job.
For example (as explained at Batch job logs),
use BatchJob.logs() in a Jupyter notebook session
to retrieve and filter the logs interactively:
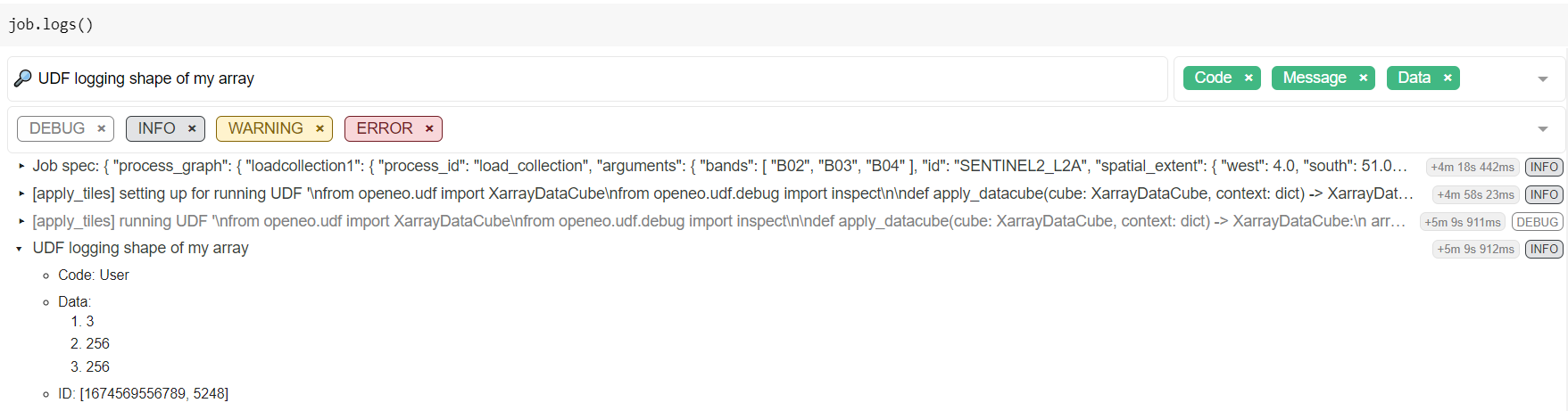
Which reveals in this example a chunking shape of [3, 256, 256].
Note
Not all kinds of data (types) are accepted/supported by the data argument of inspect,
so you might have to experiment a bit to make sure the desired debug information is logged as desired.
openeo.UDF API and usage changes in version 0.13.0#
Prior to version 0.13.0 of the openEO Python Client Library, loading and working with UDFs was a bit inconsistent and cumbersome.
The old
openeo.UDF()required an explicitruntimeargument, which was usually"Python". In the newopeneo.UDF, theruntimeargument is optional, and it will be auto-detected (from the source code or file extension) when not given.The old
openeo.UDF()required an explicitdataargument, and figuring out the correct value (e.g. something like{"from_parameter": "x"}) required good knowledge of the openEO API and processes. With the newopeneo.UDFit is not necessary anymore to provide thedataargument. In fact, while thedataargument is only still there for compatibility reasons, it is unused and it will be removed in a future version. A deprecation warning will be triggered whendatais given a value.DataCube.apply_dimension()has direct UDF support throughcodeandruntimearguments, preceding the more generic and standardprocessargument, while comparable methods likeDataCube.apply()orDataCube.reduce_dimension()only support aprocessargument with no dedicated arguments for UDFs.The goal is to improve uniformity across all these methods and use a generic
processargument everywhere (that also supports aopeneo.UDFobject for UDF use cases). For now, thecode,runtimeandversionarguments are still present inDataCube.apply_dimension()as before, but usage is deprecated.Simple example to sum it up:
udf_code = """ ... def apply_datacube(cube, ... """ # Legacy `apply_dimension` usage: still works for now, # but it will trigger a deprecation warning. cube.apply_dimension(code=udf_code, runtime="Python", dimension="t") # New, preferred approach with a standard `process` argument. udf = openeo.UDF(udf_code) cube.apply_dimension(process=udf, dimension="t") # Unchanged: usage of other apply/reduce/... methods cube.apply(process=udf) cube.reduce_dimension(reducer=udf, dimension="t")