Process graphs¶
A process graph is a chain of specific processes. Similarly to scripts in the context of programming, process graphs organize and automate the execution of one or more processes that could alternatively be executed individually. In a process graph, processes need to be specific, which means that concrete values for input parameters need to be specified. These arguments can again be process graphs (callbacks), scalar values, arrays, objects or variables.
Schematic definition¶
A process graph is defined to be a map of connected processes with exactly one node returning the final result:
<ProcessGraph> := {
<ProcessNodeIdentifier>: <ProcessNode>,
...
}
<ProcessNodeIdentifier> is a unique key across the process graph that is used to reference (the return value of) this process in arguments of other processes. The identifier is unique only across the current map of processes, so excluding any parent and child process graphs. This means all identifier are strictly scoped and can not be used in child or parent process graphs. Please note that circular references are not allowed.
Processes (Process Nodes)¶
A single node in a process graph (i.e. a specific instance of a process) is defined as follows:
<ProcessNode> := {
"process_id": <string>,
"description": <string>,
"arguments": <Arguments>,
"result": <boolean>
}
process_id and arguments (see the next section). It MAY contain a description.
One of the nodes in a map of processes (the final one) MUST have the result flag set to true, all the other nodes can omit it as the default value is false. This is important as multiple end nodes are possible, but in most use cases it is important to have exactly one end node, which can be referenced and the return value be used by other processes. Please note each callback also has a result node similar to the "main" process graph.
process_id can contain any of the process names defined by a back-end, which are all listed at GET /processes, e.g. load_collection to retrieve data from a specific collection for processing.
Arguments¶
A process can in theory have an arbitrary number of arguments. The arguments including its names and values are specified by the process specification.
Arguments are specified as an object and therefore is a simple map with key-value-pairs:
<Arguments> := {
<ParameterName>: <ArgumentValue>
}
The key <ArgumentValue> is RECOMMENDED to use snake case and MUST limit the characters to letters (a-z), numbers and underscores.
A value is defined as follows:
<ArgumentValue> := <string|number|boolean|null|array|object|Callback|CallbackParameter|Result|Variable>
Note: The specified data types except Callback, CallbackParameter, Result and Variable are the native data types supported by JSON. Limitations apply as objects are not allowed to have keys with the following names:
variable_id, except for objects of typeVariablefrom_argument, except for objects of typeCallbackParameterfrom_node, except for objects of typeResult
Important: Arrays and objects can also contain any of the data types defined above for <ArgumentValue>. So back-ends must fully traverse the process graphs, including all children.
<Result> is simply an object with a key from_node with a <ProcessNodeIdentifier> as value, which tells the back-end that the process expects the result (i.e. the return value) from another node to be passed as argument:
<Result> := {
"from_node": <ProcessNodeIdentifier>
}
Please note that the <ProcessNodeIdentifier> is strictly scoped and can only referenced from within the same process graph, i.e. can not be referenced in child or parent process graphs.
For Variable, Callback and CallbackParameter see the following sections.
Callbacks¶
Callbacks are simply specifying a process graph to be evaluated as part of another process. A callback object is a simple object with a single property callback that stores a process graph:
<Callback> := {
"callback": <ProcessGraph>
}
For example, you'd like to iterate over an array and want to apply another process abs (absolute value) on each value in the array. You can do so by executing apply in openEO (often also called map in other languages) and pass as callback the process abs, which is wrapped in a process graph.
The values passed from apply to abs are the callback parameters, which you can also "expect", similar to return values of processes (see above). You can use an object of type CallbackParameter with with a key from_argument with the callback parameter name as value:
<CallbackParameter> := {
"from_argument": <CallbackParameterName>
}
Please note that the <CallbackParameterName> is also strictly scoped and can not be referenced in child or parent process graphs.
The callback parameter names (<CallbackParameterName>) are defined by the processes. See the parameters property in the JSON schema of the parameter.
Variables¶
Process graphs can also hold a variable, which can be filled in later. For shared process graphs this can be useful to make them more portable, e.g in case a back-end specific product name would be stored with the process graph.
Variables are defined as follows:
<Variable> := {
"variable_id": <string>,
"description": <string>,
"type": <string>,
"default": <string|number|boolean|null|array|object>
}
The value for type is the expected data type for the content of the variable and MUST be one of string (default), number, boolean, array or object.
The value for variable_id is the name of the variable and can be any valid JSON key, but it is RECOMMENDED to use snake case and limit the characters to a-z, 0-9 and _.
Whenever no value for the variable is defined the default value is used or the process graph is rejected if not default value has been specified.
Example¶
Deriving minimum EVI (Enhanced Vegetation Index) measurements over pixel time series of Sentinel 2 imagery. The main process chain in blue, callbacks in yellow:
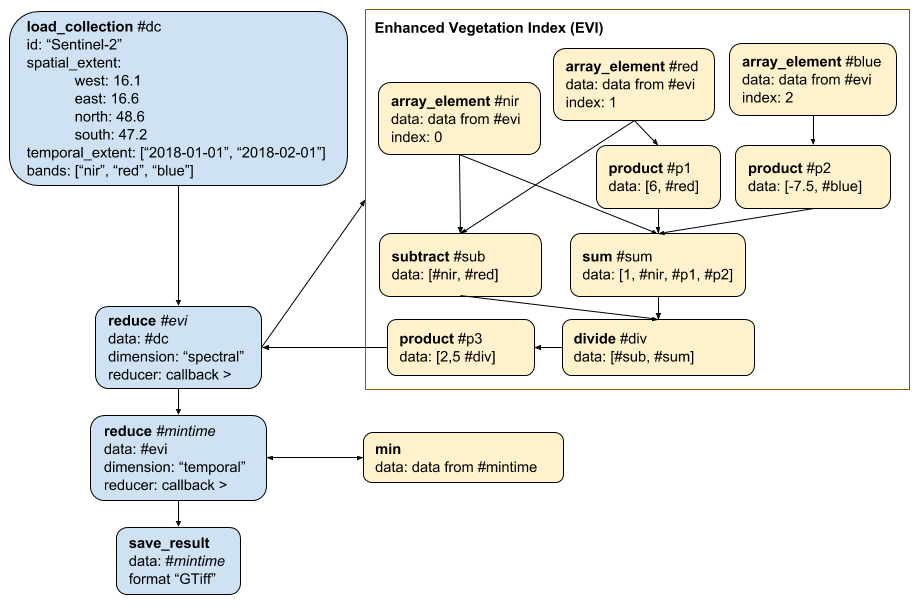
The process graph representing the algorithm:
{ "dc": { "process_id": "load_collection", "process_description": "Loading the data; The order of the specified bands is important for the following reduce operation.", "arguments": { "id": "Sentinel-2", "spatial_extent": { "west": 16.1, "east": 16.6, "north": 48.6, "south": 47.2 }, "temporal_extent": ["2018-01-01", "2018-02-01"], "bands": ["B08", "B04", "B02"] } }, "evi": { "process_id": "reduce", "process_description": "Compute the EVI. Formula: 2.5 * (NIR - RED) / (1 + NIR + 6*RED + -7.5*BLUE)", "arguments": { "data": {"from_node": "dc"}, "dimension": "spectral", "reducer": { "callback": { "nir": { "process_id": "array_element", "arguments": { "data": {"from_argument": "data"}, "index": 0 } }, "red": { "process_id": "array_element", "arguments": { "data": {"from_argument": "data"}, "index": 1 } }, "blue": { "process_id": "array_element", "arguments": { "data": {"from_argument": "data"}, "index": 2 } }, "sub": { "process_id": "substract", "arguments": { "data": [{"from_node": "nir"}, {"from_node": "red"}] } }, "p1": { "process_id": "product", "arguments": { "data": [6, {"from_node": "red"}] } }, "p2": { "process_id": "product", "arguments": { "data": [-7.5, {"from_node": "blue"}] } }, "sum": { "process_id": "sum", "arguments": { "data": [1, {"from_node": "nir"}, {"from_node": "p1"}, {"from_node": "p2"}] } }, "div": { "process_id": "divide", "arguments": { "data": [{"from_node": "sub"}, {"from_node": "sum"}] } }, "p3": { "process_id": "product", "arguments": { "data": [2.5, {"from_node": "div"}] }, "result": true } } } } }, "mintime": { "process_id": "reduce", "process_description": "Compute a minimum time composite by reducing the temporal dimension", "arguments": { "data": {"from_node": "evi"}, "dimension": "temporal", "reducer": { "callback": { "min": { "process_id": "min", "arguments": { "data": {"from_argument": "data"} }, "result": true } } } } }, "save": { "process_id": "save_result", "arguments": { "data": {"from_node": "mintime"}, "format": "GTiff" }, "result": true } }
Remarks for back-end processing¶
To process the process graph on the back-end you need to go through all nodes/processes in the list and set for each node to which node it passes data and from which it expects data. In another iteration the back-end can find all start nodes for processing by checking for zero dependencies.
You can now start and execute the start nodes (in parallel if possible). Results can be passed to the nodes that were identified beforehand. For each node that depends on multiple inputs you need to check whether all dependencies have already finished and only execute once the last dependency is ready.
Please be aware that the result node (result set to true) is not necessarily the last node that is executed. The author of the process graph may choose to set a non-end node to the result node!